As large language models (LLMs) become widely used in generative AI, their demands on underlying compute and storage infrastructure continue to rise. One that plays an outsized role—yet often goes unnoticed—is the Key-Value Cache (KV Cache).
Think of it as the “Previously on...” recap you see before each new episode in a TV series — it helps you quickly recall what happened in the last episode without having to rewatch it.
Similarly, LLMs like ChatGPT or DeepSeek must remember earlier parts of a conversation to respond coherently to new prompts. However, reprocessing the entire chat history every time would be computationally wasteful and slow. That’s where the KV Cache comes in.
The KV Cache functions as the model’s short-term memory:
When you say something new, the model compares it to the stored Key-Value pairs and quickly computes a relevant response, instead of recalculating the full attention span.
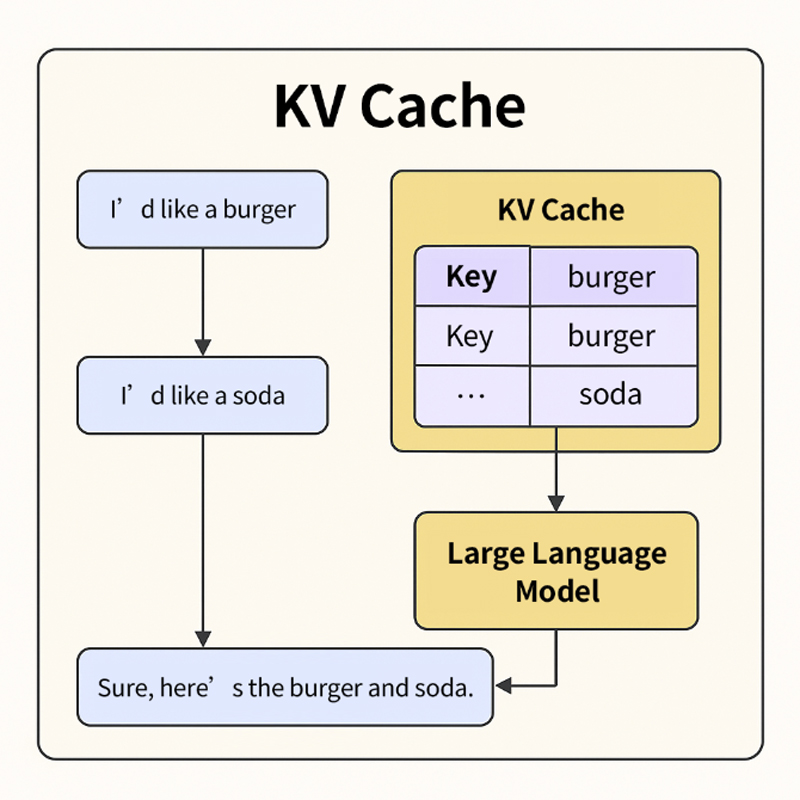
From a technical perspective, KV Cache is part of the attention mechanism in Transformer models. It caches the Key and Value tensors generated from previous inputs so that subsequent tokens can quickly query them, eliminating redundant computations on past data. This enables the model to focus on new inputs only, significantly boosting inference speed.
While KV Cache plays a smaller role during training, it becomes crucial during inference—especially in scenarios like:
Take the LLaMA2-70B model as an example. It has 80 Transformer layers, each with 64 attention heads of 128 dimensions. With FP16 precision, each token’s KV Cache consumes approximately 2.6MB of memory. That translates into:
If the model is serving multiple users—say, 10 concurrent sessions—the total KV Cache usage can easily exceed 200 GB, far beyond a typical GPU memory budget.
Additionally, inference tasks often involve temporal gaps between conversation turns. Keeping all historical KV Cache data resident in GPU or even system DRAM would be inefficient. That’s where tiered caching strategies come in: “warm and cooler” KV Cache can be evicted to NVMe SSDs, freeing up high-value memory while preserving context for later reuse. This not only boosts overall resource utilization but also lowers inference costs.
Such a design demands SSDs that can offer:

To meet the rising demands of generative AI workloads, Memblaze has introduced the PBlaze7 Series — a family of PCIe 5.0 enterprise NVMe SSDs engineered for both training and inference of large-scale models.
Exceptional Bandwidth for Parallel Access: with up to 14 GB/s sequential read and 3.3 million 4K random read IOPS, the PBlaze7 series more than doubles the throughput of typical PCIe 4.0 SSDs. This enables simultaneous KV Cache loading across numerous inference sessions, eliminating data-loading bottlenecks.
Ultra-Low Latency for Instant Retrieval: fully leverage its hardware architecture advantages, combined with deep I/O path optimization, 6-plane parallelism, and intelligent read-ahead technologies to significantly reduce read/write command latency. This results in faster response times and ensures smooth and continuous execution of every inference task—effectively eliminating lags. Compared with QLC-based SSDs, TLC flash inherently offers superior performance and consistency, making PBlaze7 a better fit for latency-sensitive workloads such as KV Cache access and checkpoint load/save operations.
Massive Capacity for Long-Context Dialogues: with models supporting capacities up to 30.72TB, the PBlaze7 can store KV Cache data for extensive user sessions or multiple 70B-scale models, without having to constantly flush or evict memory. This ensures better continuity and quality in dialogue generation.
High Endurance and Write Performance: backed by Memblaze’s in-house firmware, advanced wear leveling, and efficient garbage collection, the PBlaze7 series offers up to 11 GB/s write speed and exceptional durability. This makes it resilient to the high write-amplification workloads typical of KV Cache recycling, ensuring sustained SLA compliance.
In a tiered caching architecture, the PBlaze7 series SSDs serve as a high-speed, low-latency “external memory” layer that extends the capacity of GPUs. This is crucial for efficient and scalable LLM inference. With industry-leading performance, consistency, and endurance, Memblaze continues to empower the evolution of AI infrastructure—offering smarter storage solutions for a smarter generation of models.